音频技术
语音保存
采样数据格式
采集到模拟信号,然后通过 ADC(模数转换)将模拟信号转换成数字信号以后,再通过 PCM(Pulse Code Modulation)脉冲编码调制对连续变化的模拟信号进行采样、量化和编码转换成离散的数字信号
PCM 文件就是未经封装的音频原始文件,在输出之前,需要转换一下。这些数据的格式我们通常称之为采样数据格式
采样频率
PCM 数据的输入和输出是需要有一个频率的
- 8000 Hz 主要是电话通信时用的采样率
- 11025 Hz、22050 Hz 主要是无线电广播用的采样率
- 44100 Hz 常用于音频 CD,MP3 音乐播放等场景
- 48000 Hz 常用于 miniDV、数字电视、DVD、电影和专业音频等设备中
当采样频率 fs 大于信号中最高频率 fmax 的 2 倍时(fs > 2fmax),采样之后的数字信号才可以完整地保留原始信号中的信息
声道与布局
除了左声道、右声道,还有立体声等,当我们听到的音频声道比较多,比如听交响乐的时候,立体感会尤为明显
采样位深度
采样位深也就是每个采样点用多少 bit 来表示。决定了声音的动态范围,常见的 16 位(16bit)可以记录大概 96 分贝(96dB)的动态范围,位数越多,保真程度越高
码率
用 bps(bits per second)来表示,也就是每秒钟有多少位数据
一个 PCM 音频文件存储空间=采样位深×采样率×通道数×时长
通道数
同一时间采集或播放的音频信号的总数
音视频封装
- 无损:APE、WAV、FLAC、AIFF、ALAC、WMA
- 有损:MP3/MP3Pro、AAC、AMR、WMA、RA、OGG
语音信号
- 浊音:声带振动作为声源产生的声音
- 清音:由气体在经过唇齿等狭小区域由于空气与腔体摩擦而产生的声音
声带会振动从而产生一个声波,这个声波叫做基波,基波的频率叫做基频,也就是音调
声带振动产生的基波,在传输过程中会在声道表面反复碰撞反射,从而产生许多频率倍数于基频的声波,这些声波叫做谐波
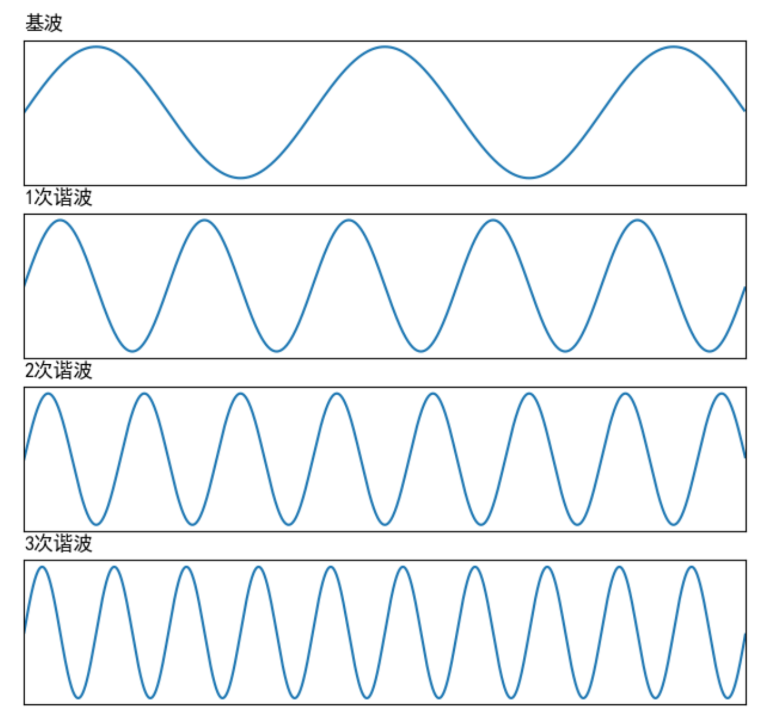
谐波频率和基频是浊音能量集中的地方
声源的振动信号通过声道时,声道本身也会发生共鸣,与声道共振频率相近的能量会被增强,远离声道共振频率的部分则会被衰减,从而谐波的能量就组成了一组高低起伏的形状包络,这些包络中的巅峰位置叫做共振峰
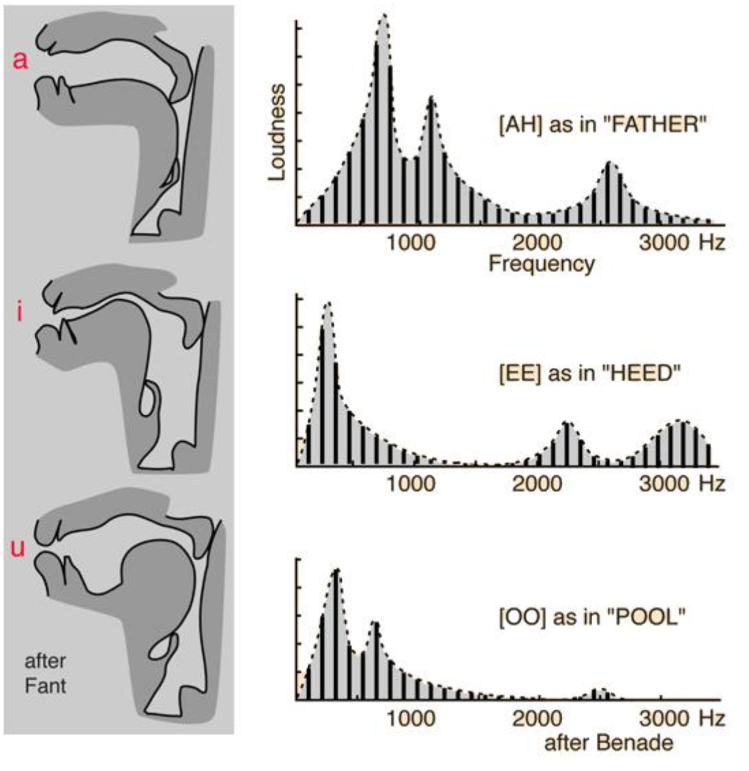
语音识别背后的原理之一是通过共振峰的位置和能量分布来识别音频代表的语音
语音信号分析
为了避免由于信号的窗口处理或者截断等操作导致频谱波形中出现能量泄漏到其他频率,一般采用加窗,即在原有信号中乘一个两端为 0 的窗信号,来减少截断信号时的频谱泄漏
时域分析:
语音的能量随时间的变化较快,比如能量小的时候可能就是没有在说话,而能量大的地方可能是语音中重读的地方,可以通过短时能量判断语音的起止位置或者韵律
$$E_n=\sum_{m=-\infty}^{\infty}\left[x(m)w(n-m)\right]^2$$
第 n 个点的短时能量 En 就是由加窗后的采样信号的平方和来表示的
短时平均过零率指的是每帧内信号通过零值的次数,背景噪声较小的情况下,短时能量比较准确;但当背景噪声比较大时,短时平均过零率有较好的效果
频域分析:
通过将语音信号进行短时傅里叶变换,将短时傅里叶变换的结果对复数频域信号求模,并取对数转换成分贝(dB),然后用热力图的形式展示出来,就是频谱图了
人耳对以 Hz 为单位的频率并不是很敏感,梅尔谱三角滤波器组把频率划分成了若干个频段。敏感的频段滤波器分布比较密集,而不敏感的频段比较稀疏,这样就能更好地表征人耳的实际听
这两种方法更能反映人耳的真实听感
音乐信号
一首曲子的节奏是由速度和节拍决定的,速度以BPM表示。
节拍用来描述音乐中的进程的规律,指有一定强弱分别的一系列拍子,在每隔一定时间重复出现。若干个这样有规律的拍子叫一个小节
乐器的演奏其实就是按照节拍规定的音符演奏顺序,然后按照指定的速度演奏出来
| 唱名 | do | re | mi | fa | So | la | ti | do |
|---|---|---|---|---|---|---|---|---|
| 音名 | C4 | D4 | E4 | F4 | G4 | A4 | B4 | C5 |
| 基频频率(Hz) | 261.6 | 293.7 | 329.6 | 349.2 | 392.0 | 440.0 | 493.9 | 523.2 |
音频评价
主观评价
- MUSHRA(Multi-Stimulus Test with Hidden Reference and Anchor,多激励隐藏参考基准测试方法):在测试语料中混入无损音源作为参考(上限),全损音源作为锚点(下限),通过双盲听测试,对待测音源和隐藏参考音源与锚点进行主观评分
客观评价
- 有参考质量评价:PESQ、POLQA
- 无参考质量评价:ITU-T P.563、ANIQUE+、E-model、ITU-T P.1201
音频降噪
- 加性噪声:由噪声和源信号相加得到的,信号和噪声是不相关的。又可以按照噪声是否平稳,分为稳态噪声和非稳态噪声
- 乘性噪声:噪声和信号是相关联的,比如信号的衰减、房间的混响、多普勒效应等
线性滤波器
事先知道噪声会在哪个频段出现,采用一些比如高通滤波器来消除低频噪声、用一些陷波滤波器来消除某些频段的持续噪声
谱减法
先取一段非人声段音频,记录下噪声的频谱能量,然后从所有的音频频谱中减去这个噪声频谱能量
基于统计模型的实时降噪算法
利用统计的方法估算出音频频谱中每个频点所对应的噪声和语音的分量,是假设在噪声是比较平稳的情况上
子空间算法
针对一些已知噪声类型,量身定做一个降噪算法,把噪声和人声投影到一个高纬度的空间,让本来不容易分离的信号变成在高纬度占据一个可分的子空间,从而可分的信号
基于机器学习的降噪
通过数据训练的方式,训练人工神经网络来进行降噪
f(带噪音的音频) = 不带噪音的音频
一般用纯净的语音作为目标或者说标签,然后用纯净语音加入一些噪声生成含噪数据
传统降噪中,维纳滤波等方法,都是通过计算先验信噪比,然后在频域上对每一个频谱的频点都乘以一个小于等于 1 的系数来抑制噪声。这些在频域上乘的系数统称为频域掩码。而如何计算这个频域掩码就成了解决降噪问题的关键
机器学习的任务就是计算出频域掩码
回声消除
$$z'(n)=f(x(n))-f'(x(n))+y(n)$$
- z'(n):消除了回声的声音
- x(n):远端接收到的参考信号
- f:回声路径的传递函数
- y(n):近端声音
回声消除算法的目的就是通过算法估计出回声路径的传递函数f
自适应滤波器
用实时更新的滤波器的系数来模拟真实场景的回声路径,然后结合远端信号来估计出回声信号,再从近端采集的混合信号中减去估计的回声,从而达到消除回声的目的
- 最小均方算法 LMS(Least Mean Square)
- NLMS
网络传输
编解码器
mindmap root((音频编解码器常见指标)) 码率 音质 主观听感 采样率 采样位深 通道数 计算复杂度 编码耗时 解码耗时 延迟 算法延迟 一包多帧
- 语音编解码器:对语音的发声来建模进行编解码
- 音乐编解码器:从听得清晰的角度利用心理听觉来进行编码,人耳更敏感的频带需要多耗费一些码率来编码,不敏感的则少耗费一些码率
弱网对抗
- FEC(Forward Error Correction):发送端通过信道编码和发送冗余信息,而接收端检测丢包,以更高的信道带宽作为恢复丢包的开销
- ARQ(Automatic Repeat-reQuest):类似于 TCP 中的请求重传
NetEQ模块:主要包括两个模块:MCU(Micro Control Unit,微控制单元)和 DSP(Digital Signal Prcessing,信号处理单元),通过再 MCU 开辟一个比较大的缓冲区域,让一段时间内到来的数据包进行存储排序,再交给解码器进行解码
空间音频
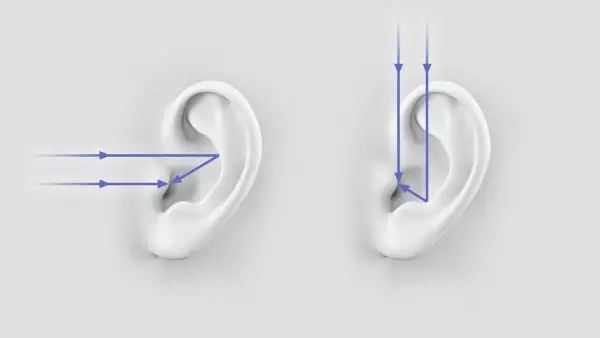
人耳的耳廓在接收不同方向的音源时,会让声波以不同的路径传导至内耳。这样,不同方向的声波传输到内耳的时候,音色就会由于耳廓的形状而产生各向异性
如果音源在你的左侧,那么左耳会先接收到声波;相反如果音源在右侧,右耳会先收到声音。同时由于人的头部也会对声音的传播产生影响,如果音源在左侧,那么声波需要越过头部这个“障碍”才能传递到右耳,那么相对于左耳,音色和能量可能都会有所衰减
这是空间音频里常说的“双耳效应”,即依靠双耳间的音量差、时间差和音色差来判别声音方位的效应
人耳对距离的感知是相对的。比如声音播放时音量由小变大,我们会感觉声音在靠近
空间音频的采集
- 人工头:通过仿生模型,构建人头和耳廓、耳道等部位,然后通过人工头上的人工耳中内置的麦克风来采集空间音频
- 入耳式麦克风:直接把左右耳道接收到的音频给录下来
- Ambisonics:把整个空间的声场都录下来,从而在回放的时候,你可以转动自己的头聆听任意方向的声音,那么就需要另一套叫做高保真度立体声像复制(Ambisonics)的技术
空间音频的播放
- 用耳机来还原空间音频相对比较准确
HRTF
预先把空间中不同位置声源的空间传递函数都测量并记录下来,然后利用这个空间传递函数,我们只需要有一个普通的单声道音频以及这个音源和听音者所在虚拟空间中的位置信息,就可以用预先采集好的空间传递函数来渲染出左右耳的声音
音频特效
- 变调:变调其实就是要改变基频,而基频的本质是一个信号的循环周期的倒数,变调其实就是把这个循环周期进行扩大或者缩小
- 均衡器:一组滤波器,比如常见的高通、低通、带通、带阻等
- 混响
音频AI
- ASR(Automatic Speech Recognition):将语音转为信号序列,根据特征序列推断出对应的音素序列,最后再转为文本。
- 为了实现比较准确的 ASR 系统,需要构建两个主要的模型:声学模型(Acoustic Model)和语言模型(Language model)。然后通过语言解码器和搜索算法(Ligusitic Decoding and search algorithm),结合声学模型和语言模型的结果,综合选择出概率最大的文字序列作为识别的输出
- TTS(Text To Speech):通过一个模型把文字转为语音的特征向量,再使用声码器(Vocoder)把语音特征转换为音频信号
- VPR(Voice Print Recognition):把说话人的声音特点编码成固定长度的向量(SpeakerEmbeding)