数据库优化
对于优化最重要的事是测量,如果优化的成本高于收益,就要停止优化。
优化原因
- 避免网站出现访问错误
- 低效的查询导致数据库不稳定
- 优化用户体验
优化方面
- 硬件
- 系统配置
- 数据库表结构
- SQL与索引
成本从下到上递增,效果从上到下递减
MYSQL优化
监控
性能剖析 show profile(逐渐淘汰)
一条SQL语句结束后
使用show profile查询剖析工具,可以指定具体的type
show profile cpu;all:显示所有性能信息
block io:显示块io操作的次数
context switches:显示上下文切换次数,被动和主动
cpu:显示用户cpu时间、系统cpu时间
IPC:显示发送和接受的消息数量
memory:内存
page faults:显示页错误数量
source:显示源码中的函数名称与位置
swaps:显示swap的次数
show status则可以查看相关计数器数据,计数器数据价值相较于profile低。
使用performance schema
通过该数据库直接通过sql就能得到服务器相关的一些测量信息
使用show processlist查看连接的线程个数
开启慢查询
慢查询日志式开销最低,精度最高的测量查询时间的工具
set global slow_query_log=ON; #开启慢查询set global long_query_time=1.0; #设置记录时长为1秒set global log_queries_not_using_indexes = ON; #不适用索引慢查询日志地址:
地址存储在slow_query_log_file变量中
慢查询日志存储格式
# Time: 2019-11-29T06:01:43.909217Z 执行时间# User@Host: root[root] @ localhost [] Id: 9 主机信息# Query_time: 0.104442 查询时间 Lock_time: 0.000153 锁定时间 Rows_sent: 1 发送行数 Rows_examined: 16249 锁扫描行数SET timestamp=1575007303; 执行时间戳select count(*) from actor,payment; SQL慢查询分析工具
- mysqldumpslow
mysqldumpslow -t 10 日志地址 # 分析前10条记录- pt-query-digest
wget percona.com/get/pt-query-digest # 下载chmod u+x pt-query-digest # 添加执行权限/pt-query-digest 慢查询日志地址 # 分析日志问题定位
- 次数多、时间长
- IO大
- 未命中索引
数据库结构优化
- 选择合适的数据类型
- 范式化
- 反范式化
垂直拆分
| ID | Name | Avatar |
|---|---|---|
| 1 | Shaun | <Binaries> |
| 2 | Lucy | <Binaries> |
| 3 | Linda | <Binaries> |
| 4 | Mary | <Binaries> |
| 5 | Tom | <Binaries> |
↓
| ID | Name |
|---|---|
| 1 | Shaun |
| 2 | Lucy |
| 3 | Linda |
| 4 | Mary |
| 5 | Tom |
| Avatar | ID |
|---|---|
<Binaries> | 1 |
<Binaries> | 2 |
<Binaries> | 3 |
<Binaries> | 4 |
<Binaries> | 5 |
使用垂直切分将按数据库中表的密集程度部署到不同的库中
切分后部分表无法join,只能通过接口方式解决,提高了系统复杂度,存在分布式事务问题
水平拆分
| ID | Name |
|---|---|
| 1 | Shaun |
| 2 | Lucy |
| 3 | Linda |
| 4 | Mary |
| 5 | Tom |
↓
| ID | Name |
|---|---|
| 1 | Shaun |
| 2 | Lucy |
| 3 | Linda |
| ID | Name |
|---|---|
| 4 | Mary |
| 5 | Tom |
当一个表的数据不断增多时,水平拆分是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力
分库分表
同上面的水平拆分,每张表或者每个库只存储一定量的数据,当需要进行数据读写时,根据唯一ID取模得到数据的位置
为什么分库分表能提高性能
将一张表的数据拆分成多个n张表进行存放,然后使用第三方中间件(MyCat或者Sharding-JDBC)可以并行查询
一些分库分表中间件
cobar,tddl,atlas,sharing-jdbc,my-cat
系统迁移到分库分表
如何将一个单库单表的系统动态迁移到分库分表上去
- 停机迁移
禁止全部数据写入,编写一个程序,将单库单表的数据写到分库分表上:
- 应用程序预先实现分库分表的支持
- 停机暂停所有流量接入
- 启动脚本,循环读取数据,将每一条数据按照既定规则写入到新库,直至完成
- 应用程序切换到新库上
- 恢复,继续接收流量
- 双写迁移
新系统部署后,每条数据都会在老库和新库写一遍
双写切换流程:
- 刚开始只读写老库
- 切换到读写老库的同时,开始往新库写一遍数据
- 切换到只写老库,开始启用新库读写
- 完成切换,不再写老库,只用新库读写
同时还需要一个校验与修复脚本持续不断运行,将老库与新库不一致的数据修复,把老库更新到新库的条件是:老库有的数据新库没有,或者是老库的数据更新时间比新库的新
工具会比较新库与老库的每一条数据,只有每条数据都一致,才算完成,否则持续运行校验,这样脚本几轮操作过去后,新老库的数据就一致了
动态扩容缩容的分库分表方案
- 停机扩容
同上,只不过上面那是从单个数据库到多个数据库,这次这个是多个数据库到多个数据库但是不推荐这种做法,原因是数据量很大,数据很难在短时间内转移完毕
- 第一次分库分表,就一次性给他分个够
32 个库,每个库 32 个表这里可以多个库都在同一台机器上,当不够用的时候,可以将这些库转移到新机器上这样,数据的逻辑位置没有发生改变,也避免扩容缩容带来的数据迁移问题
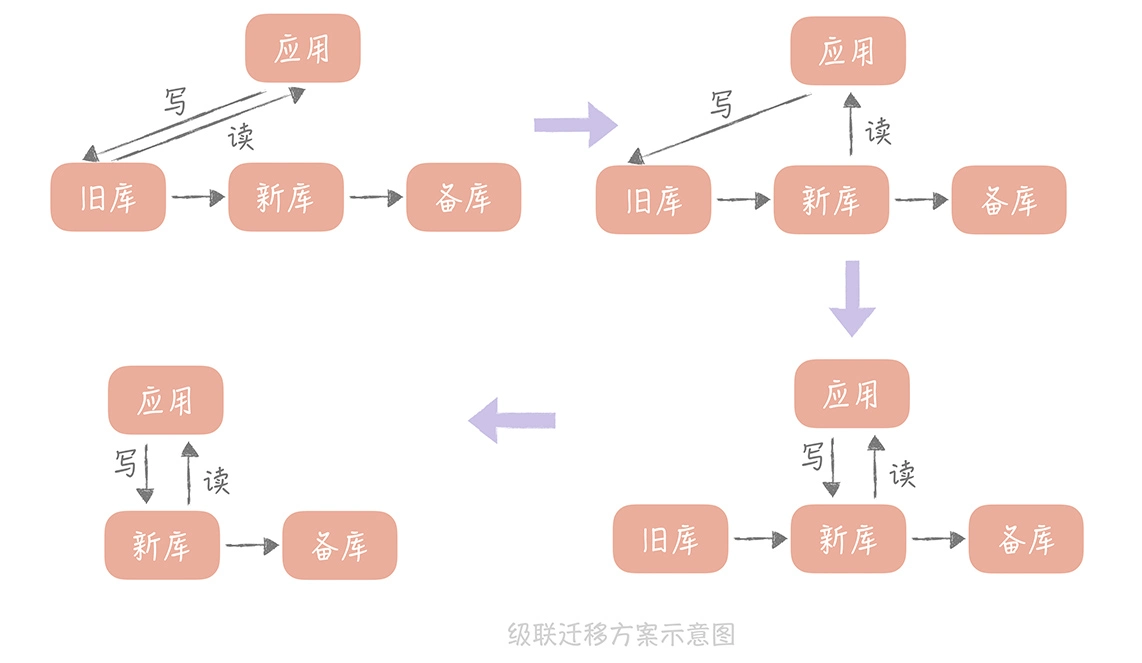
- 级联同步迁移
比较适合数据从自建机房向云上迁移的场景,在切写的时候需要短暂的停止写入
唯一ID生成
- 使用一个单点系统来做自增ID的获取
- 必须要能应对时钟回拨,或者服务器异常重启之后计数器不会重复的问题
- redis、数据库自带的自增
- 多个节点的ID获取无法并行
- 使用多个单点系统,每个系统自增ID设置相同的步长不同的初始值,这样就能保证这些节点ID不会重复
- 但这种方式注定了节点数量不能变化
为了避免每次生成都需要一次调用,在需要产生新的全局 ID 的时候,每次单点服务都向数据库批量申请 n 个 ID,在本地用内存维护这个号段,并把数据库中的 ID 修改为当前值 +n,直到这 n 个 ID 被耗尽;下次需要产生新的全局 ID 的时候,再次到数据库申请一段新的号段
- UUID
- UUID组成部分:当前日期和时间+时钟序列+随机数+全局唯一的IEEE机器识别号
- 比较长,无法保证趋势递增,做索引时查询效率低
- 系统时间
- 可以使用业务字段来拼接避免重复
- 雪花算法
- 一个 64 位的 long 型的 id,第一个 bit 是不用的,用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号
- 单个节点内无法并行
- 多个节点可以并行
- 可以支撑每秒400万+的ID生成,在某些实现里,如果某一毫秒内的计数器被耗尽达到上限,会死循环直至这 1ms 过去
拆分策略
使用水平拆分时,操作一条数据,要在哪张表找到它
- 哈希取模
- 范围,ID范围,时间范围
- 映射表
拆分后的问题
- 事务
- 使用分布式事务
- 连接
- 原来的连接需要分解成多个单表查询,在应用层进行连接
- ID唯一性
- 全局唯一ID(GUID)
- 每个分片指定ID范围
- 分布式ID生成器,雪花算法
一个查询的执行顺序
(8) SELECT (9)DISTINCT<select list>(1) FROM <left table>(3) <join_type>JOIN<right_table>(2) ON<join condition>(4) WHERE<where condition>(5) GROUP BY<group_by_list>(6) WITH (CUBE|ROLLUP)(7) HAVING<having condition>(10) ORDER BY<order by_list>(11) LIMIT <limit number>- FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON: 对虚表VT1进行ON筛选,只有那些符合`
`的行才会被记录在虚表VT2中。 - JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
- WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合`
`的记录才会被插入到虚拟表VT4中。 - GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
- CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
- HAVING: 对虚拟表VT6应用having过滤,只有符合`
`的记录才会被 插入到虚拟表VT7中。
- SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
- ORDER BY: 将虚拟表VT9中的记录按照`
`进行排序操作,产生虚拟表VT10. - LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。