深度学习
- 深度学习在本质上解决什么问题?
- 各类神经网络模型之间为什么不同、差异来自哪里?
- 模型为何不断演进,哪些思想是稳定的、可迁移的?
一、深度学习的第一性原理
1.1 本质定义
深度学习的本质是:
在高维空间中,使用可组合、可微的参数化函数族,近似复杂数据分布或条件映射关系,并通过梯度优化寻找具有泛化能力的解。
其核心不在于“层数深”,而在于:
- **函数复合**(Representation Composition)
- **结构化假设**(Inductive Bias)
- **可优化性**(Differentiable Optimization)
1.2 三个根本矛盾
- **表达能力 vs 泛化能力** 模型越复杂,越容易过拟合
- **理论最优 vs 计算可行** 全局最优不可达,只能近似搜索
- **数据规模 vs 模型复杂度** 数据决定模型上限,结构决定效率
所有模型设计,本质上都是在这三者之间取平衡。
二、统一认知框架:归纳偏置视角
不同神经网络并非“功能不同的黑箱”,而是对数据结构作出了不同假设。
2.1 归纳偏置的核心维度
| 维度 | 说明 |
|---|---|
| 输入结构假设 | 向量 / 序列 / 网格 |
| 参数共享方式 | 无共享 / 时间共享 / 空间共享 |
| 依赖建模范围 | 局部 / 全局 |
| 记忆机制 | 无 / 显式 / 门控 |
| 学习范式 | 判别式 / 生成式 |
后续所有模型,都可放入这一坐标系中理解。
三、无结构假设:感知机与前馈网络
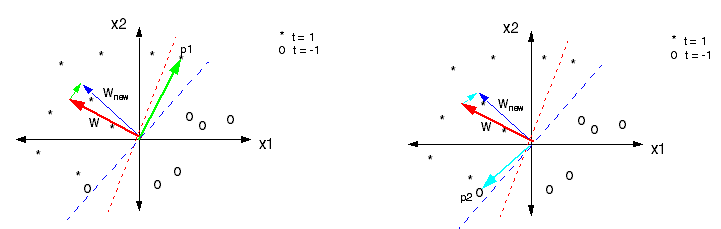
3.1 感知机模型
问题假设:数据线性可分 结构设计:线性加权 + 阈值判断
[ w_i(t+1)=w_i(t)+\eta[d_j-y_j(t)]\cdot x_{j,i} ]
感知机的历史意义不在于能力,而在于:
- 首次将“学习”形式化为参数更新
- 奠定了梯度优化思想基础
3.2 深度前馈网络(MLP)
问题假设:输入是独立同分布的向量 核心思想:多层非线性函数复合
- 信息单向流动(前馈)
- 非线性来自激活函数
- 表达能力随层数指数提升
前馈网络解决的是:
从线性模型到通用函数逼近器的跃迁
四、表示学习:自编码器体系
4.1 自编码器(AutoEncoder)
自编码器是一类无监督表示学习模型。
[ \phi,\psi=\arg\min_{\phi,\psi}||\mathbf{X}-(\phi\circ\psi)(\mathbf{X})||^2 ]
信息论视角:
- 编码:有损压缩
- 解码:重构信号
- 目标:在压缩与重构误差之间取得最优平衡
自编码器的本质贡献是:
将“特征工程”内生化为模型结构本身
五、优化的本质与训练动力学
5.1 深度模型中的优化难题
- 病态矩阵:数值不稳定
- 局部极值:非凸目标
- 鞍点:高维空间的主要障碍
这些问题并非“实现缺陷”,而是高维非凸优化的必然结果。
5.2 随机梯度下降(SGD)
核心思想:
用噪声换取可扩展性
- 小批量近似真实梯度
- 噪声既是问题,也是正则化手段
常见改进:
- Momentum
- Accelerated Gradient
- Adam(自适应学习率)
六、空间归纳偏置:卷积神经网络(CNN)
6.1 卷积层
- 局部感受野
- 参数共享
- 平移不变性假设
6.2 卷积神经网络
CNN 的核心不是“卷积运算”,而是:
对空间局部性和层级结构的强假设
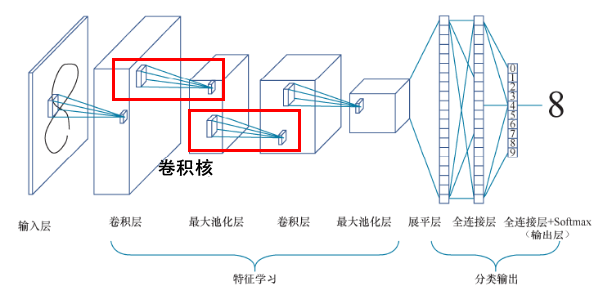
CNN 的成功来源于:
- 极强的结构约束
- 极低的有效参数维度
七、时间归纳偏置:序列与递归结构
7.1 循环神经网络(RNN)
[ \mathbf{h}_t=f(\mathbf{W}\mathbf{x}t+\mathbf{U}\mathbf{h}{t-1}) ]
本质:时间维度上的参数共享
问题:
- 梯度消失 / 爆炸
7.2 长短期记忆网络(LSTM)
LSTM 通过门控机制:
- 控制信息流
- 显式管理长期记忆
其意义在于:
将“记忆”从隐式状态提升为可控结构
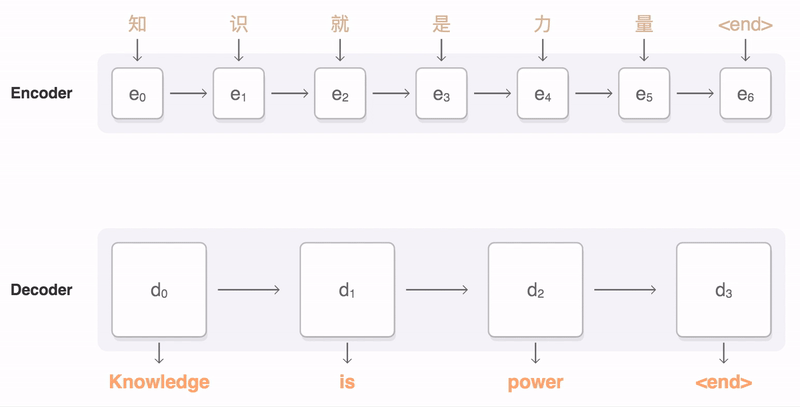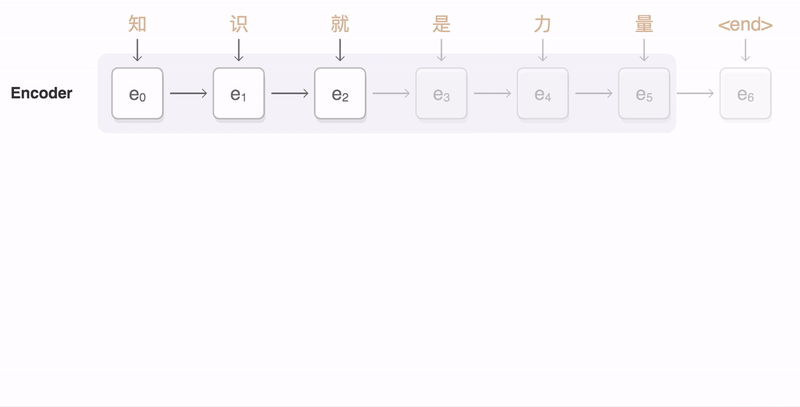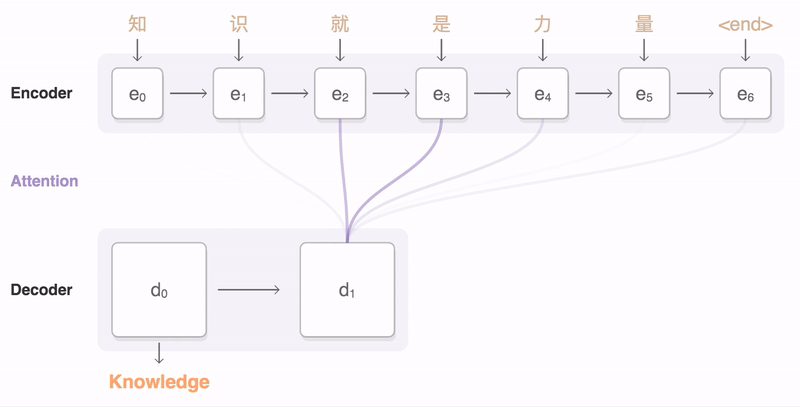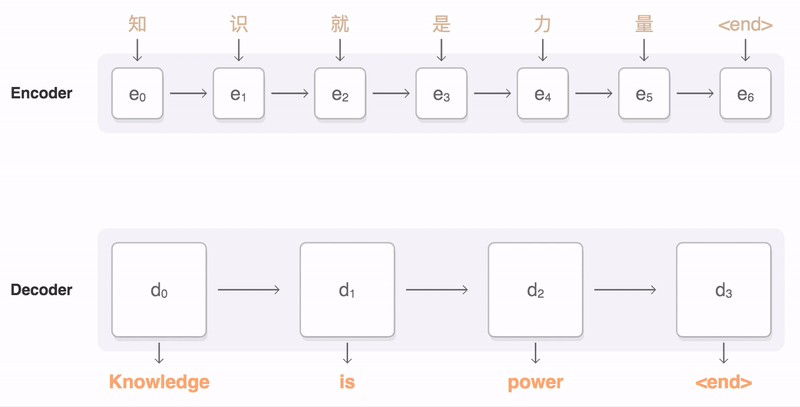
7.3 seq2seq 与注意力
- 编码器:压缩序列语义
- 解码器:生成目标序列
- 注意力:打破固定长度瓶颈
八、从序列到全局:Transformer
Transformer 的革命性在于:
- 放弃递归
- 通过 Attention 建模全局依赖
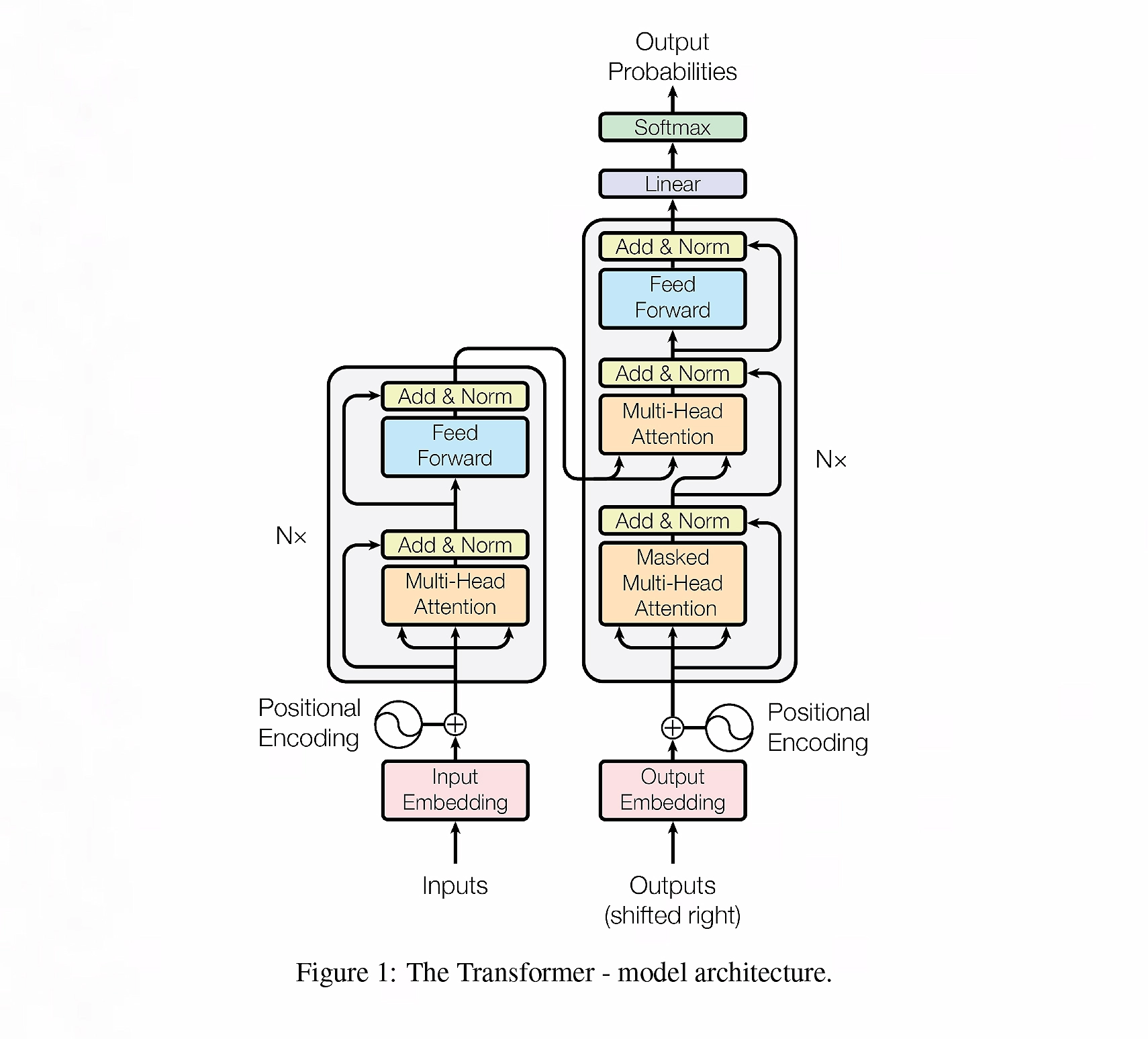
其本质优势是:
计算路径最短化 + 并行化最大化
九、生成式与概率视角模型
9.1 深度信念网络(DBN)
- 基于概率图模型
- 核心单元:受限玻尔兹曼机
历史意义大于现实应用。
9.2 生成式对抗网络(GAN)
- 生成器:拟合数据分布
- 判别器:区分真伪
[ \arg\min_g\max_D-\dfrac12\int_x[p_{data}(x)\log(D(x))+p_g(x)\log(1-D(x))],dx ]
GAN 的思想价值在于:
将学习转化为博弈过程
十、补充模型:特定归纳假设的探索
- 径向基神经网络:局部响应假设
- 自组织映射(SOM):拓扑保持映射
- 模糊神经网络:不确定性建模
这些模型逐渐淡出主流,但其思想被继承。
十一、表示学习总结
表示学习的统一目标:
学习对任务有用、对噪声不敏感、可迁移的中间表示
深度学习的未来,不在于更多模型,而在于:
- 更合理的结构假设
- 更稳定的优化动力学
- 更可解释的表示空间
关联内容(自动生成)
- [/数据技术/机器学习.html](/数据技术/机器学习.html) 深度学习是机器学习的一个重要分支,两者在模型优化、泛化能力等方面有密切关系
- [/数据技术/特征工程.html](/数据技术/特征工程.html) 深度学习中的表示学习与特征工程中的自动特征提取技术密切相关
- [/数据技术/监督学习.html](/数据技术/监督学习.html) 深度学习模型通常用于解决监督学习任务,如分类和回归问题
- [/数据技术/推荐系统.html](/数据技术/推荐系统.html) 深度学习在推荐系统中用于学习用户和物品的复杂表示
- [/数学/线性代数.html](/数学/线性代数.html) 线性代数是深度学习的数学基础,特别是矩阵与向量运算在神经网络中的应用
- [/数学/概率论与数理统计.html](/数学/概率论与数理统计.html) 概率论为深度学习中的不确定性建模和贝叶斯方法提供理论基础
- [/数据技术/非监督学习.html](/数据技术/非监督学习.html) 深度学习在无监督学习领域有重要应用,如自编码器和生成模型
- [/数据技术/数据处理.html](/数据技术/数据处理.html) 深度学习模型的训练和推理需要高效的数据处理框架支持
- [/编程语言/python.html](/编程语言/python.html) Python是深度学习领域的主要编程语言,拥有丰富的深度学习框架和库
- [/计算机系统/数字逻辑电路.html](/计算机系统/数字逻辑电路.html) 神经网络加速器(NPU)等硬件为深度学习模型提供计算支持