分解单块系统
单体地狱
早期单体架构的好处:
- 应用开发简单
- 易于大规模更改
- 测试部署扩展简单
随着应用的不断丰富,单体暴露出了下列问题:
- 复杂性
- 影响开发效率
- 扩展难
- 错误无法隔离,软件变得不那么可靠
定义微服务架构
- 定义系统操作:根据用户需求
- 命令操作
- 查询操作
- 定义服务
- 定义服务API与协作方式
拆分单体
根据改变速度,团队结构,安全需求以及实现技术等对其进行分离
绞杀单体应用:
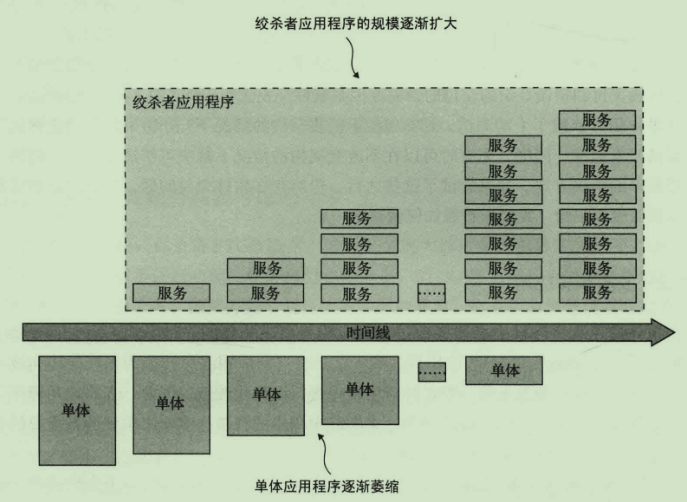
拆分维度
- 压力模型:隔离高频低频并发流量
- 主线支线链路模型:隔离主链路业务与直线业务链路
- [DDD](/软件工程/领域驱动设计.html)
- 用户群体模型:隔离不同类型的用户
- 基于安全边界
- 基于技术异构
停止挖掘
当开发新功能时不应该为旧单体应用添加新代码,最佳方法应该是将新功能开发成独立微服务
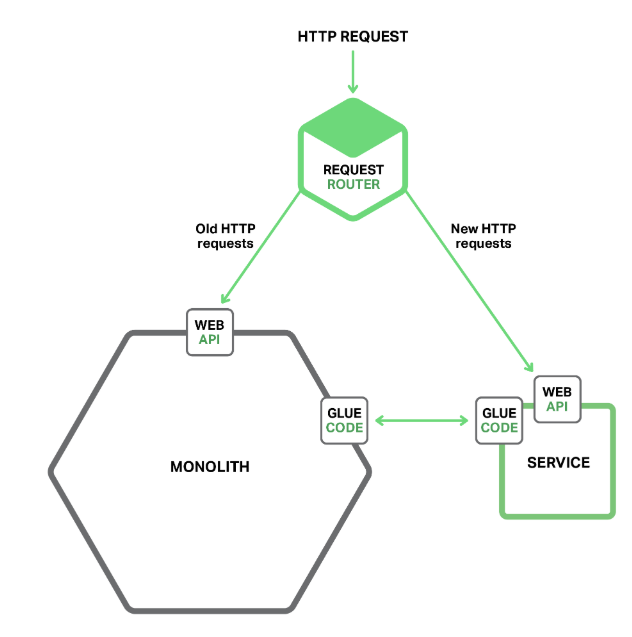
前后端分离
将单体应用进行前后端分离,有两个好处:
- 使得可以接入微服务
- 界面与业务逻辑可以独立部署
抽出服务
- 对抽取成服务的模块进行优先级排序
- 经常变化的业务逻辑
- 资源消耗大户
- 粗粒度边界
- 抽取模块
- 定义粗粒度接口
- 将调用变为远程调用
与单体协作
单体重构的过程中,微服务肯定需要与单体进行协作,需要定义好一个它们之间的协作方式。
- 集成胶水API
- 进程间通信接口
- 反腐层:建立一个中间层,避免不同领域的概念相互污染
- 维护好数据一致性
- 身份验证与授权机制
拆分服务
- 扩展
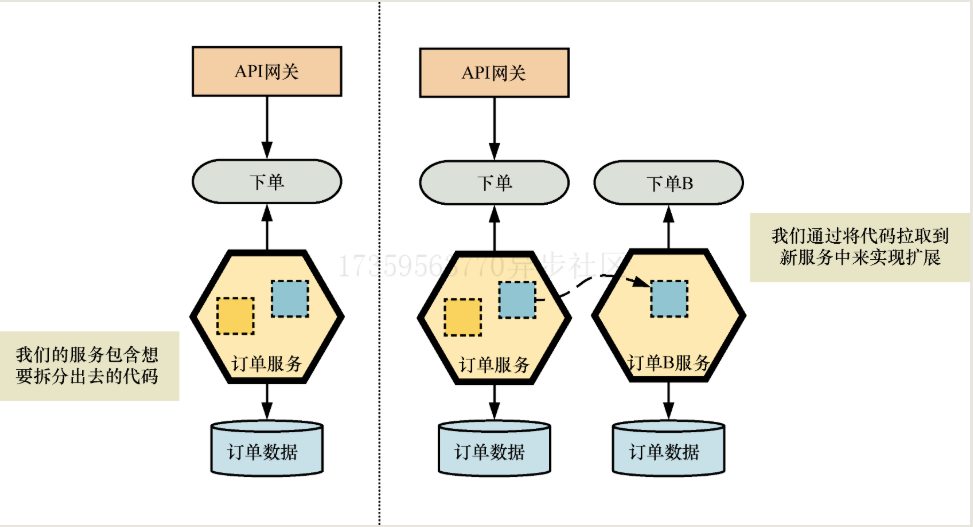
- 迁移
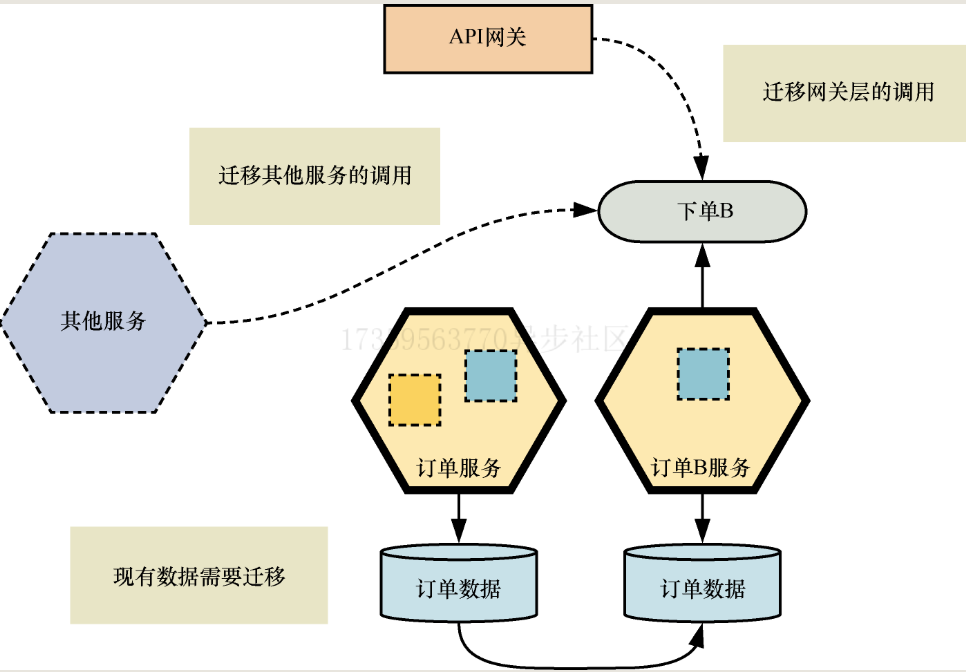
- 收缩
- 删除原先服务的无用代码
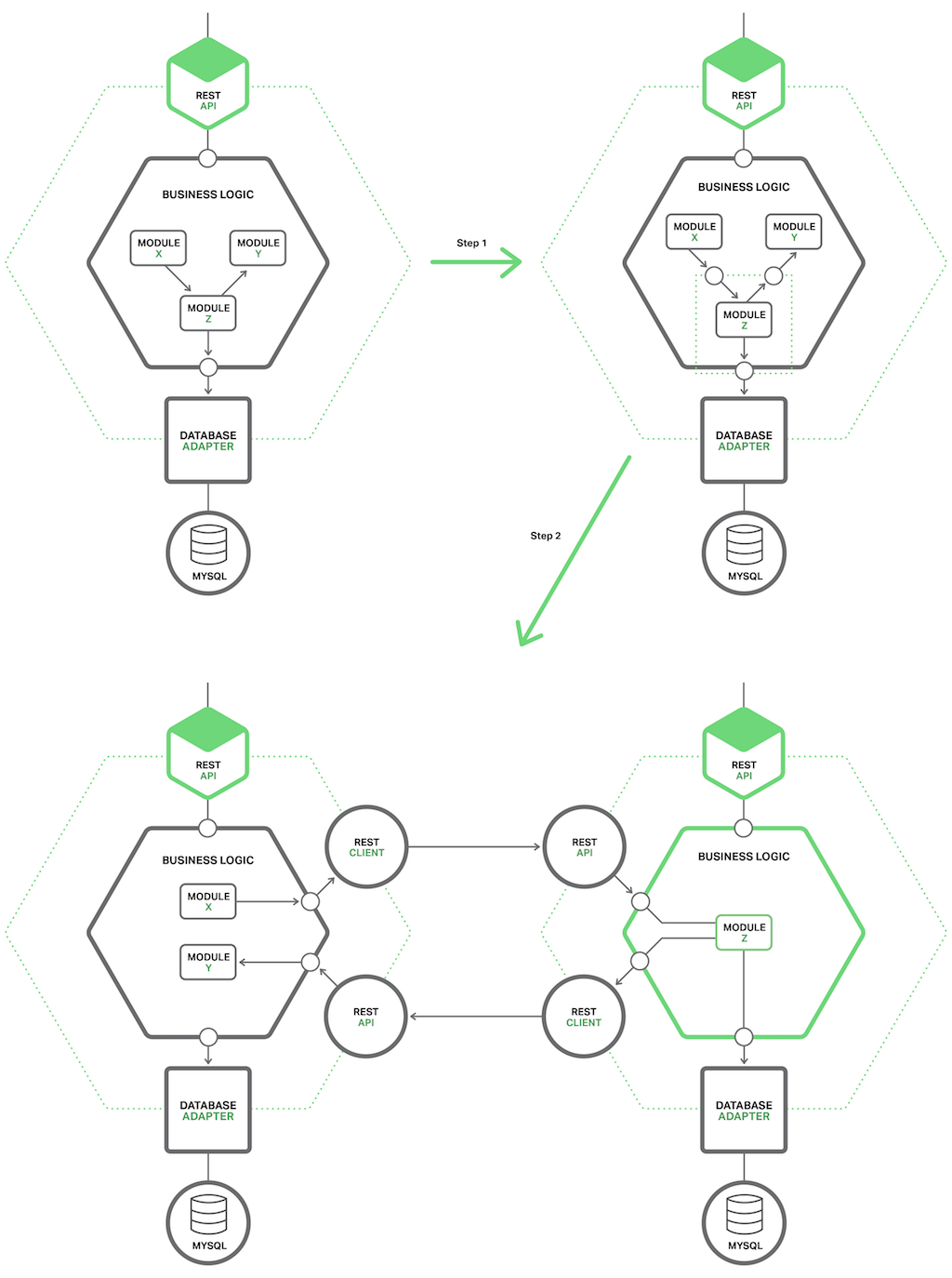
那么如何将对应的系统操作拆分为独立的服务?
根据业务能力
组织的业务是做什么。
从业务能力到服务的映射是一个非常主观的判断。围绕业务能力建模的好处在于最终的架构会趋于稳定。
- 根据子域
利用DDD子域的概念来避免不同子领域复用相同术语所带来的混乱。
基于扩展性
将已经成熟和改动不大的服务拆分为稳定服务,将经常变化和迭代的服务拆分为变动服务
基于可靠性
将可靠性要求高的核心服务和可靠性要求低的非核心服务拆分开来,然后重点保证核心服务的高可用
基于性能需求
将性能要求高或者性能压力大的模块拆分出来,避免性能压力大的服务影响其他服务
服务API定义
- 将系统操作分配给服务
- 确定服务所暴露的API
依赖处理
数据库
- 分析数据库表的依赖关系,把不同的表或者不同的数据分到不同的限界上下文里
外键
放弃,改用api调用来实现数据查询
共享数据
- 静态数据
如果要求不苛刻,可以使用配置文件,否则使用一个专门的服务器来管理静态数据
- 动态数据
独立出一个服务,专门来处理
- 共享表
需要重新审视设计,进行分表操作
数据库重构
先分离数据库再分离服务,虽然这样会破坏事务完整性,但是可以保证随时可以回退
事务
分离数据库之后,如何保证事务的安全性?
如果一个事务中的部分操作成功,部分操作失败,该如何?
- 再试一次
- 也就是最终一致性,如果失败了,将其放入队列,稍后重试
- 终止操作
- 发起一个补偿事务,来撤销成功的操作
- 但是如果补偿事务再失败的话,可以引入重试或者人工操作
- 分布式事务
- 也就是两阶段提交,每个事务参与者需要向事务管理器投票,如果所有参与者都同意,则事务管理器告诉所有参与者提交,否则只要有一个不同意,则所有事务参与者都有放弃此次事务
引入这些都会增加系统的复杂性,最好的方式是避免这种跨服务的事务
报表问题
如果分离了数据库,那么如何解决需要所有数据的后台报表应用?
- 服务调用
- SQL接口
- 提供一个批量API
- 指导系统将数据写入到一个共享位置来解决传输问题
- 数据导出
- 由服务主动推送数据到报表服务器
- 事件数据导出
- 当服务发生事件时,服务主动推送这些事件到一个中间件上
拆分单体到服务的难点
- 网络延迟
- 同步通信导致的可用性降低
- 数据一致性问题
- 不同子域对同一业务实体复用造成的上帝类